(換膚)
語言:

文章編號:11308時間:2024-09-30人氣:
AWStats 是一款免費且開源的 Web 服務(wù)器日志分析工具,可為網(wǎng)站管理員提供有關(guān)網(wǎng)站訪問者行為的寶貴見解。
通過分析 Web 服務(wù)器日志文件,AWStats 可以生成易于理解的報告,其中包含有關(guān)以下內(nèi)容的信息:
AWStats 報告由多個部分組成,每個部分提供不同類型的見解。
概覽部分提供了網(wǎng)站流量的總體摘要,包括訪客數(shù)量、訪問次數(shù)、每位訪客的頁面瀏覽量以及平均停留時間。
“按日期”
今天安裝了awstats(AWStats是在Sourceforge上發(fā)展很快的一個基于Perl的WEB日志分析工具。 ),好好折騰了一把,終于搞完了,參考了不少資料,將主要步驟和遇到的問題分享一下。
1.在home下建一個目錄awstats,cd /home/awstats
下載awstats最新版本7.0
3.安裝
復(fù)制代碼
代碼如下:
[root@JMAppSer tools]# perl awstats_
----- AWStats awstats_configure 1.0 (build 1.9) (c) Laurent Destailleur -----
This tool will help you to configure AWStats to analyze statistics for
one web server. You can Try to use it to let it do all that is possible
in AWStats setup, however following the step by step manual setup
documentation (docs/) is often a better idea. Above all if:
- You are not an administrator user,
- You want to analyze downloaded log files without web server,
- You want to analyze mail or ftp log files instead of web log files,
- You need to analyze load balanced servers log files,
- You want to understand all possible ways to use AWStats...
Read the AWStats documentation (docs/).
----- Running OS detected: Linux, BSD or Unix
----- Check for web server install
Found Web server Apache config file /usr/local/apache/conf/
----- Check and complete web server config file /usr/local/apache/conf/
Add Alias /awstatsclasses /usr/local/awstats/wwwroot/classes/
Add Alias /awstatscss /usr/local/awstats/wwwroot/css/
Add Alias /awstatsicons /usr/local/awstats/wwwroot/icon/
Add ScriptAlias /awstats/ /usr/local/awstats/wwwroot/cgi-bin/
Add Directory directive
AWStats directives added to Apache config file.
----- Update model config file /usr/local/awstats/wwwroot/cgi-bin/
File updated.
----- Need to create a new config file ?
Do you want me to build a new AWStats config/profile
file (required if First install) [y/N] ? y
----- Define config file name to create
What is the name of your web site or profile analysis ?
Example: demo
Your web site, virtual server or profile name:
----- Define config file path
In which directory do you plan to store your config file(s) ?
Default: /etc/awstats
Directory path to store config file(s) (Enter for default):
/usr/local/awstats/config
----- Create config file /usr/local/awstats/config/
Config file /usr/local/awstats/config/ created.
----- Restart Web server with /sbin/service httpd restart
Usage: /etc/init.d/httpd [-D name] [-d directory] [-f file]
[-C directive] [-c directive]
[-k start|restart|graceful|graceful-stop|stop]
[-v] [-V] [-h] [-l] [-L] [-t] [-S]
-D name : define a name for use in IfDefine name directives
-d directory : specify an alternate initial ServerRoot
-f file : specify an alternate ServerConfigFile
-C directive : process directive before reading config files
-c directive : process directive after reading config files
-e level : show startup errors of level (see LogLevel)
-E file : log startup errors to file
-v : show version number
-V : show compile settings
-h : list available command line options (this page)
-l : list compiled in modules
-L : list available configuration directives
-t -D DUMP_VHOSTS : show parsed settings (currently only vhost settings)
-S : a synonym for -t -D DUMP_VHOSTS
-t -D DUMP_MODULES : show all loaded modules
-M : a synonym for -t -D DUMP_MODULES
-t : run syntax check for config files
----- Add update process inside a scheduler
Sorry, does not support automatic add to cron yet.
You can do it manually by adding the following command to your cron:
/usr/local/awstats/wwwroot/cgi-bin/ -update -config=
Or if you have several config files and prefer having only one command:
/usr/local/awstats/tools/awstats_ now
Press ENTER to continue...
A SIMPLE config file has been created: /usr/local/awstats/config/
You should have a look inside to check and change manually main parameters.
You can then manually update your statistics for with command:
perl -update -config=
You can also read your statistics for with URL:
Press ENTER to finish...
[root@JMAppSer tools]# cp /usr/loca/awstats/wwwroot/icon /usr/local/apache/htdocs/awstatsicons -rf
cp: 無法 stat “/usr/loca/awstats/wwwroot/icon”: 沒有那個文件或目錄
[root@JMAppSer tools]#
[root@JMAppSer tools]#
[root@JMAppSer tools]# ls
awstats_ awstats_ geoip_ nginx webmin
awstats_ awstats_ httpd_conf xslt
[root@JMAppSer tools]# cd ..
[root@JMAppSer awstats]# ls
awstats-7.0 awstats-7.1 config docs tools wwwroot
[root@JMAppSer awstats]# ll
總計 1508
drwxr-xr-x 5 1000 1000 4096 2010-12-06 awstats-7.0
drwxr-xr-x 5 root root 4096 11-22 17:52 awstats-7.1
-rw-r--r-- 1 root root 11-22 18:02
drwxr-xr-x 2 root root 4096 11-25 10:21 config
drwxr-xr-x 4 root root 4096 11-22 18:04 docs
-rw-r--r-- 1 root root 6787 11-22 18:04
drwxr-xr-x 5 root root 4096 11-22 18:04 tools
drwxr-xr-x 7 root root 4096 11-22 18:04 wwwroot
[root@JMAppSer awstats]# cd wwwroot/
[root@JMAppSer wwwroot]# ls
cgi-bin classes css icon js
[root@JMAppSer wwwroot]# cp icon/ /usr/local/jiemai/apache-blogs/htdocs/awstatsicons -rf
[root@JMAppSer wwwroot]#
[root@JMAppSer wwwroot]#
[root@JMAppSer wwwroot]# pwd
/usr/local/awstats/wwwroot
[root@JMAppSer wwwroot]# cd ..
[root@JMAppSer awstats]# ls
awstats-7.0 awstats-7.1 config docs tools wwwroot
[root@JMAppSer awstats]# ls
awstats-7.0 awstats-7.1 config docs tools wwwroot
[root@JMAppSer awstats]# ll
總計 1508
drwxr-xr-x 5 1000 1000 4096 2010-12-06 awstats-7.0
drwxr-xr-x 5 root root 4096 11-22 17:52 awstats-7.1
-rw-r--r-- 1 root root 11-22 18:02
drwxr-xr-x 2 root root 4096 11-25 10:21 config
drwxr-xr-x 4 root root 4096 11-22 18:04 docs
-rw-r--r-- 1 root root 6787 11-22 18:04
drwxr-xr-x 5 root root 4096 11-22 18:04 tools
drwxr-xr-x 7 root root 4096 11-22 18:04 wwwroot
[root@JMAppSer awstats]# cd config/
[root@JMAppSer config]# ls
[root@JMAppSer config]# vi
# AWSTATS CONFIGURE FILE 7.0
# Copy this file into and edit this new config file
# to setup AWStats (See documentation in docs/ directory).
# The config file must be in /etc/awstats, /usr/local/etc/awstats or /etc (for
# Unix/Linux) or same directory than (Windows, Mac, Unix/Linux...)
# To include an environment variable in any parameter (AWStats will replace
# it with its value when reading it), follow the example:
# Parameter=__ENVNAME__
# Note that environment variable AWSTATS_CURRENT_CONFIG is always defined with
# the config value in an AWStats running session and can be used like others.
# $Revision: 1.353 $ - $Author: eldy $ - $Date: 2012/02/15 14:19:22 $
# MAIN SETUP SECTION (Required to make AWStats work)
# LogFile contains the web, ftp or mail server log file to analyze.
# Possible values: A full path, or a relative path from directory.
# Example: /var/log/apache/
# Example: ../logs/
# You can also use tags in this filename if you need a dynamic file name
# depending on date or time (Replacement is made by AWStats at the beginning
# of its execution). This is available tags :
# %YYYY-n is replaced with 4 digits year we were n hours ago
# %YY-n is replaced with 2 digits year we were n hours ago
# %MM-n is replaced with 2 digits month we were n hours ago
# %MO-n is replaced with 3 letters month we were n hours ago
# %DD-n is replaced with day we were n hours ago
# %HH-n is replaced with hour we were n hours ago
# %NS-n is replaced with number of seconds at 00:00 since 1970
# %WM-n is replaced with the week number in month (1-5)
# %Wm-n is replaced with the week number in month (0-4)
# %WY-n is replaced with the week number in year (01-52)
# %Wy-n is replaced with the week number in year (00-51)
# %DW-n is replaced with the day number in week (1-7, 1=sunday)
# use n=24 if you need (1-7, 1=monday)
# %Dw-n is replaced with the day number in week (0-6, 0=sunday)
# use n=24 if you need (0-6, 0=monday)
# Use 0 for n if you need current year, month, day, hour...
# Example: /var/log/access_log.%YYYY-0%MM-0%
# Example: C:/WINNT/system32/LogFiles/W3SVC1/ex%YY-24%MM-24%
# You can also use a pipe if log file come from a pipe :
# Example: gzip -d /var/log/apache/ |
# If there are several log files from load balancing servers :
# Example: /pathtotools/ * |
#LogFile=/var/log/httpd/
LogFile=/usr/local/jiemai/apache-blogs/logs/access_logs
# Note: Result of DNS Lookup can be used to build the Country report. However
# it is highly recommanded to enable the plugin geoip or geoipfree to
# have an accurate Country report with no need of DNS Lookup.
# Possible values:
# 0 - No DNS Lookup
# 1 - DNS Lookup is fully enabled
# 2 - DNS Lookup is made only from static DNS cache file (if it exists)
# Default: 2
DNSLookup=2
# When AWStats updates its statistics, it stores results of its analysis in
# files (AWStats
# Relative or absolute web URL of your awstats cgi-bin directory.
# This parameter is used only when AWStats is run from command line
# with -output option (to generate links in HTML reported page).
# Example: /awstats
# Default: /cgi-bin (means is in /yourwwwroot/cgi-bin)
DirCgi=/usr/local/awstats/wwwroot/cgi-bin
/AllowToUpdateStatsFromBrowser
# When this parameter is set to 1, AWStats adds a button on report page to
# allow to update statistics from a web browser. Warning, when update is
# made from a browser, AWStats is run as a CGI by the web server user defined
# in your web server (user nobody by default with Apache, IUSR_XXX with
# IIS), so the DirData directory and all already existing history files
# awstatsMMYYYY[] must be writable by this user. Change permissions if
# necessary to Read/Write (and Modify for Windows NTFS file systems).
# Warning: Update process can be long so you might experience time out
# browser errors if you dont launch AWStats frequently enough.
# When set to 0, update is only made when AWStats is run from the command
# line interface (or a task scheduler).
# Possible values: 0 or 1
# Default: 0
AllowToUpdateStatsFromBrowser=1
# AWStats saves and sorts its target=_blank> 1557L, C written
[root@JMAppSer config]# chown -R root:root /usr/local/awstats
[root@JMAppSer config]# chmod -R 755 /usr/local/awstats
[root@JMAppSer config]# mkdir /usr/local/awstats/data
[root@JMAppSer config]# chown /usr/local/awstats/data
[root@JMAppSer config]# chmod 777
DirData=/usr/local/awstats/data
DirCgi=/usr/local/awstats/wwwroot/cgi-bin
AllowToUpdateStatsFromBrowser=1
6.設(shè)置權(quán)限
chown -R root:root /usr/local/awstats
chmod -R 755 /usr/local/awstats
mkdir /usr/local/awstats/data
chown /usr/local/awstats/data
chmod 777 data
chmod 755 /usr/local/awstats/wwwroot/cgi-bin/*
7.生成分析日志與靜態(tài)查看界面
cd /usr/local/awstats/wwwroot/cgi-bin
perl -config=上面域名 -update -lang=cn
perl -config=上面域名 -output -staticlinks -lang=cnawstats.上面
8.測試 http:// 上面的域名/awstats/?config=上面的域名
遇到的問題:
-config=上面域名 -update -lang=cn提示出錯,或在測試時提示出錯。LogFormat不正確:
原因:access_logs格式不正確,刪除access_logs,重啟APACHE。搞定
2.測試時看圖片顯示不了。
原因:/etc/awstats/awstats.上面輸入的中的DirIcons配置不正確,這個目錄一定要從/usr/local/apache/htdocs目錄開始算,相對目錄,要確保配置的目錄可能過http訪問到
3.點擊測試頁面的“立即更新”時,提示無法存儲
原因:/usr/local/awstats/data的權(quán)限不正確,需要使用nobody權(quán)限,賦777.
手工識別和拒絕爬蟲的訪問相當(dāng)多的爬蟲對網(wǎng)站會造成非常高的負(fù)載,因此識別爬蟲的來源IP是很容易的事情。 最簡單的辦法就是用netstat檢查80端口的連接:netstat -nt | grep youhostip:80 | awk {print $5} | awk -F: {print $1}| sort | uniq -c | sort -r -n 這行shell可以按照80端口連接數(shù)量對來源IP進行排序,這樣可以直觀的判斷出來網(wǎng)頁爬蟲。 一般來說爬蟲的并發(fā)連接非常高。 如果使用lighttpd做Web Server,那么就更簡單了。 lighttpd的mod_status提供了非常直觀的并發(fā)連接的信息,包括每個連接的來源IP,訪問的URL,連接狀態(tài)和連接時間等信息,只要檢查那些處于handle-request狀態(tài)的高并發(fā)IP就可以很快確定爬蟲的來源IP了。 拒絕爬蟲請求既可以通過內(nèi)核防火墻來拒絕,也可以在web server拒絕,比方說用iptables拒絕:iptables -A INPUT -i eth0 -j Drop -p tcp --dport 80 -s 84.80.46.0/24直接封鎖爬蟲所在的C網(wǎng)段地址。 這是因為一般爬蟲都是運行在托管機房里面,可能在一個C段里面的多臺服務(wù)器上面都有爬蟲,而這個C段不可能是用戶寬帶上網(wǎng),封鎖C段可以很大程度上解決問題。 通過識別爬蟲的User-Agent信息來拒絕爬蟲有很多爬蟲并不會以很高的并發(fā)連接爬取,一般不容易暴露自己;有些爬蟲的來源IP分布很廣,很難簡單的通過封鎖IP段地址來解決問題;另外還有很多各種各樣的小爬蟲,它們在嘗試google以外創(chuàng)新的搜索方式,每個爬蟲每天爬取幾萬的網(wǎng)頁,幾十個爬蟲加起來每天就能消耗掉上百萬動態(tài)請求的資源,由于每個小爬蟲單獨的爬取量都很低,所以你很難把它從每天海量的訪問IP地址當(dāng)中把它準(zhǔn)確的挖出來。 這種情況下我們可以通過爬蟲的User-Agent信息來識別。 每個爬蟲在爬取網(wǎng)頁的時候,會聲明自己的User-Agent信息,因此我們就可以通過記錄和分析User-Agent信息來挖掘和封鎖爬蟲。 我們需要記錄每個請求的User-Agent信息,對于Rails來說我們可以簡單的在app/controllers/里面添加一個全局的before_filter,來記錄每個請求的User-Agent信息 HTTP_USER_AGENT #{[HTTP_USER_AGENT]}然后統(tǒng)計每天的,抽取User-Agent信息,找出訪問量最大的那些User-Agent。 要注意的是我們只關(guān)注那些爬蟲的User-Agent信息,而不是真正瀏覽器User-Agent,所以還要排除掉瀏覽器User-Agent,要做到這一點僅僅需要一行shell:grep HTTP_USER_AGENT | grep -v -E MSIE|Firefox|Chrome|Opera|Safari|Gecko | sort | uniq -c | sort -r -n | head -n 100 > 統(tǒng)計結(jié)果類似這樣: HTTP_USER_AGENT Baiduspider+(+HTTP_USER_AGENT Mozilla/5.0 (compatible; Googlebot/2.1; +HTTP_USER_AGENT Mediapartners-Google HTTP_USER_AGENT msnbot/2.0b (+從日志就可以直觀的看出每個爬蟲的請求次數(shù)。 要根據(jù)User-Agent信息來封鎖爬蟲是件很容易的事情,lighttpd配置如下:$HTTP[useragent] =~ qihoobot|^Java|Commons-HttpClient|Wget|^PHP|Ruby|Python { = ( ^/(.*) => / )}使用這種方式來封鎖爬蟲雖然簡單但是非常有效,除了封鎖特定的爬蟲,還可以封鎖常用的編程語言和HTTP類庫的User-Agent信息,這樣就可以避免很多無謂的程序員用來練手的爬蟲程序?qū)W(wǎng)站的騷擾。 還有一種比較常見的情況,就是某個搜索引擎的爬蟲對網(wǎng)站爬取頻率過高,但是搜索引擎給網(wǎng)站帶來了很多流量,我們并不希望簡單的封鎖爬蟲,僅僅是希望降低爬蟲的請求頻率,減輕爬蟲對網(wǎng)站造成的負(fù)載,那么我們可以這樣做:$HTTP[user-agent] =~ Baiduspider+ {-seconds = 10}對網(wǎng)絡(luò)的爬蟲請求延遲10秒鐘再進行處理,這樣就可以有效降低爬蟲對網(wǎng)站的負(fù)載了。 通過網(wǎng)站流量統(tǒng)計系統(tǒng)和日志分析來識別爬蟲有些爬蟲喜歡修改User-Agent信息來偽裝自己,把自己偽裝成一個真實瀏覽器的User-Agent信息,讓你無法有效的識別。 這種情況下我們可以通過網(wǎng)站流量系統(tǒng)記錄的真實用戶訪問IP來進行識別。 主流的網(wǎng)站流量統(tǒng)計系統(tǒng)不外乎兩種實現(xiàn)策略:一種策略是在網(wǎng)頁里面嵌入一段js,這段js會向特定的統(tǒng)計服務(wù)器發(fā)送請求的方式記錄訪問量;另一種策略是直接分析服務(wù)器日志,來統(tǒng)計網(wǎng)站訪問量。 在理想的情況下,嵌入js的方式統(tǒng)計的網(wǎng)站流量應(yīng)該高于分析服務(wù)器日志,這是因為用戶瀏覽器會有緩存,不一定每次真實用戶訪問都會觸發(fā)服務(wù)器的處理。 但實際情況是,分析服務(wù)器日志得到的網(wǎng)站訪問量遠(yuǎn)遠(yuǎn)高于嵌入js方式,極端情況下,甚至要高出10倍以上。 現(xiàn)在很多網(wǎng)站喜歡采用awstats來分析服務(wù)器日志,來計算網(wǎng)站的訪問量,但是當(dāng)他們一旦采用Google Analytics來統(tǒng)計網(wǎng)站流量的時候,卻發(fā)現(xiàn)GA統(tǒng)計的流量遠(yuǎn)遠(yuǎn)低于awstats,為什么GA和awstats統(tǒng)計會有這么大差異呢?罪魁禍?zhǔn)拙褪前炎约簜窝b成瀏覽器的網(wǎng)絡(luò)爬蟲。 這種情況下awstats無法有效的識別了,所以awstats的統(tǒng)計數(shù)據(jù)會虛高。 其實作為一個網(wǎng)站來說,如果希望了解自己的網(wǎng)站真實訪問量,希望精確了解網(wǎng)站每個頻道的訪問量和訪問用戶,應(yīng)該用頁面里面嵌入js的方式來開發(fā)自己的網(wǎng)站流量統(tǒng)計系統(tǒng)。 自己做一個網(wǎng)站流量統(tǒng)計系統(tǒng)是件很簡單的事情,寫段服務(wù)器程序響應(yīng)客戶段js的請求,分析和識別請求然后寫日志的同時做后臺的異步統(tǒng)計就搞定了。 通過流量統(tǒng)計系統(tǒng)得到的用戶IP基本是真實的用戶訪問,因為一般情況下爬蟲是無法執(zhí)行網(wǎng)頁里面的js代碼片段的。 所以我們可以拿流量統(tǒng)計系統(tǒng)記錄的IP和服務(wù)器程序日志記錄的IP地址進行比較,如果服務(wù)器日志里面某個IP發(fā)起了大量的請求,在流量統(tǒng)計系統(tǒng)里面卻根本找不到,或者即使找得到,可訪問量卻只有寥寥幾個,那么無疑就是一個網(wǎng)絡(luò)爬蟲。 分析服務(wù)器日志統(tǒng)計訪問最多的IP地址段一行shell就可以了:grep Processing | awk {print $4} | awk -F. {print $1.$2.$3.0} | sort | uniq -c | sort -r -n | head -n 200 > stat_然后把統(tǒng)計結(jié)果和流量統(tǒng)計系統(tǒng)記錄的IP地址進行對比,排除真實用戶訪問IP,再排除我們希望放行的網(wǎng)頁爬蟲,比方Google,網(wǎng)絡(luò),微軟msn爬蟲等等。 最后的分析結(jié)果就就得到了爬蟲的IP地址了。 以下代碼段是個簡單的實現(xiàn)示意:whitelist = [](#{RAILS_ROOT}/lib/) { |line| whitelist << [0] if line }realiplist = [](#{RAILS_ROOT}/log/visit_) { |line|realiplist << if line }iplist = [](#{RAILS_ROOT}/log/stat_) do |line|ip = [1] << ip if [0]_i > 3000 && !?(ip) && !?(ip)end _crawler(iplist)分析服務(wù)器日志里面請求次數(shù)超過3000次的IP地址段,排除白名單地址和真實訪問IP地址,最后得到的就是爬蟲IP了,然后可以發(fā)送郵件通知管理員進行相應(yīng)的處理。 網(wǎng)站的實時反爬蟲防火墻實現(xiàn)策略通過分析日志的方式來識別網(wǎng)頁爬蟲不是一個實時的反爬蟲策略。 如果一個爬蟲非要針對你的網(wǎng)站進行處心積慮的爬取,那么他可能會采用分布式爬取策略,比方說尋找?guī)装偕锨€國外的代理服務(wù)器瘋狂的爬取你的網(wǎng)站,從而導(dǎo)致網(wǎng)站無法訪問,那么你再分析日志是不可能及時解決問題的。 所以必須采取實時反爬蟲策略,要能夠動態(tài)的實時識別和封鎖爬蟲的訪問。 要自己編寫一個這樣的實時反爬蟲系統(tǒng)其實也很簡單。 比方說我們可以用memcached來做訪問計數(shù)器,記錄每個IP的訪問頻度,在單位時間之內(nèi),如果訪問頻率超過一個閥值,我們就認(rèn)為這個IP很可能有問題,那么我們就可以返回一個驗證碼頁面,要求用戶填寫驗證碼。 如果是爬蟲的話,當(dāng)然不可能填寫驗證碼,所以就被拒掉了,這樣很簡單就解決了爬蟲問題。 用memcache記錄每個IP訪問計數(shù),單位時間內(nèi)超過閥值就讓用戶填寫驗證碼,用Rails編寫的示例代碼如下:ip_counter = (_ip)if !ip_(_ip, 1, :expires_in => )elsif ip_counter > 2000render :template => test, :status => 401 and return falseend這段程序只是最簡單的示例,實際的代碼實現(xiàn)我們還會添加很多判斷,比方說我們可能要排除白名單IP地址段,要允許特定的User-Agent通過,要針對登錄用戶和非登錄用戶,針對有無referer地址采取不同的閥值和計數(shù)加速器等等。 此外如果分布式爬蟲爬取頻率過高的話,過期就允許爬蟲再次訪問還是會對服務(wù)器造成很大的壓力,因此我們可以添加一條策略:針對要求用戶填寫驗證碼的IP地址,如果該IP地址短時間內(nèi)繼續(xù)不停的請求,則判斷為爬蟲,加入黑名單,后續(xù)請求全部拒絕掉。 為此,示例代碼可以改進一下:before_filter :ip_firewall, :except => :testdef ip_firewallrender :file => #{RAILS_ROOT}/public/, :status => 403 if ?(ip_sec)end我們可以定義一個全局的過濾器,對所有請求進行過濾,出現(xiàn)在黑名單的IP地址一律拒絕。 對非黑名單的IP地址再進行計數(shù)和統(tǒng)計:ip_counter = (_ip)if !ip_(_ip, 1, :expires_in => )elsif ip_counter > 2000crawler_counter = (crawler/#{_ip})if !crawler_(crawler/#{_ip}, 1, :expires_in => )elsif crawler_counter > (ip_sec)render :file => #{RAILS_ROOT}/public/, :status => 403 and return falseendrender :template => test, :status => 401 and return falseend如果某個IP地址單位時間內(nèi)訪問頻率超過閥值,再增加一個計數(shù)器,跟蹤他會不會立刻填寫驗證碼,如果他不填寫驗證碼,在短時間內(nèi)還是高頻率訪問,就把這個IP地址段加入黑名單,除非用戶填寫驗證碼激活,否則所有請求全部拒絕。 這樣我們就可以通過在程序里面維護黑名單的方式來動態(tài)的跟蹤爬蟲的情況,甚至我們可以自己寫個后臺來手工管理黑名單列表,了解網(wǎng)站爬蟲的情況。 關(guān)于這個通用反爬蟲的功能,我們開發(fā)一個開源的插件:這個策略已經(jīng)比較智能了,但是還不夠好!我們還可以繼續(xù)改進:1、用網(wǎng)站流量統(tǒng)計系統(tǒng)來改進實時反爬蟲系統(tǒng)還記得嗎?網(wǎng)站流量統(tǒng)計系統(tǒng)記錄的IP地址是真實用戶訪問IP,所以我們在網(wǎng)站流量統(tǒng)計系統(tǒng)里面也去操作memcached,但是這次不是增加計數(shù)值,而是減少計數(shù)值。 在網(wǎng)站流量統(tǒng)計系統(tǒng)里面每接收到一個IP請求,就相應(yīng)的(key)。 所以對于真實用戶的IP來說,它的計數(shù)值總是加1然后就減1,不可能很高。 這樣我們就可以大大降低判斷爬蟲的閥值,可以更加快速準(zhǔn)確的識別和拒絕掉爬蟲。 2、用時間窗口來改進實時反爬蟲系統(tǒng)爬蟲爬取網(wǎng)頁的頻率都是比較固定的,不像人去訪問網(wǎng)頁,中間的間隔時間比較無規(guī)則,所以我們可以給每個IP地址建立一個時間窗口,記錄IP地址最近12次訪問時間,每記錄一次就滑動一次窗口,比較最近訪問時間和當(dāng)前時間,如果間隔時間很長判斷不是爬蟲,清除時間窗口,如果間隔不長,就回溯計算指定時間段的訪問頻率,如果訪問頻率超過閥值,就轉(zhuǎn)向驗證碼頁面讓用戶填寫驗證碼。 最終這個實時反爬蟲系統(tǒng)就相當(dāng)完善了,它可以很快的識別并且自動封鎖爬蟲的訪問,保護網(wǎng)站的正常訪問。 不過有些爬蟲可能相當(dāng)狡猾,它也許會通過大量的爬蟲測試來試探出來你的訪問閥值,以低于閥值的爬取速度抓取你的網(wǎng)頁,因此我們還需要輔助第3種辦法,用日志來做后期的分析和識別,就算爬蟲爬的再慢,它累計一天的爬取量也會超過你的閥值被你日志分析程序識別出來。
1.通過awstats分析apache日志(或者NGINX日志,含使用代理日志分析)2.借助GEOIP分析到國家名稱3.借助和QQ純真IP庫分析IP所在中國的具體區(qū)域!
AWStats是在Sourceforge上發(fā)展很快的一個基于Perl的WEB日志分析工具。
Awstats是一個功能強大且個性化的免費網(wǎng)站日志分析工具,特別適合于深入了解您網(wǎng)站的流量和用戶行為。它能夠提供詳盡的數(shù)據(jù)統(tǒng)計,包括:
總之,Awstats是一個全面且易于使用的工具,能夠為您的網(wǎng)站運營和優(yōu)化提供強大的數(shù)據(jù)支持。
內(nèi)容聲明:
1、本站收錄的內(nèi)容來源于大數(shù)據(jù)收集,版權(quán)歸原網(wǎng)站所有!
2、本站收錄的內(nèi)容若侵害到您的利益,請聯(lián)系我們進行刪除處理!
3、本站不接受違法信息,如您發(fā)現(xiàn)違法內(nèi)容,請聯(lián)系我們進行舉報處理!
4、本文地址:http://www.lmxpnzry.com/article/ea1938b879b8baf928f4.html,復(fù)制請保留版權(quán)鏈接!

簡介DataGrid控件是許多應(yīng)用程序中常用的功能,它允許用戶查看和選擇數(shù)據(jù)集中的行,DataGrid提供了多種行選擇機制,以滿足不同應(yīng)用程序的需求,本文檔將提供有關(guān)DataGrid行選擇機制的詳細(xì)指南,單行選擇單行選擇是最簡單的選擇機制,它允許用戶一次只選擇一行,要啟用單行選擇,請將DataGrid的`SelectionMode`屬...。
本站公告 2024-09-29 18:50:36

在PHP中,四舍五入是一個常見的操作,但如果處理不當(dāng),可能會導(dǎo)致意外的結(jié)果,為什么四舍五入會出現(xiàn)問題,PHP中四舍五入最常見的陷阱源于浮點運算誤差,浮點運算是一種近似計算,可能會導(dǎo)致微小的誤差,從而影響四舍五入的結(jié)果,避免陷阱的方法1.使用PHP的內(nèi)置函數(shù)PHP提供了一系列內(nèi)置函數(shù)用于四舍五入,這些函數(shù)可以處理浮點運算誤差,`roun...。
本站公告 2024-09-23 11:20:07

概述當(dāng)Vue組件被創(chuàng)建時,它會經(jīng)歷一個稱為生命周期的過程,生命周期是一系列鉤子函數(shù),允許您在組件的不同階段執(zhí)行特定操作,本文將重點介紹兩個關(guān)鍵的生命周期鉤子,`mounted`和`updated`,Mounted鉤子`mounted`鉤子在組件首次掛載到DOM時調(diào)用,此時,組件的DOM元素已經(jīng)創(chuàng)建并且可以訪問,何時使用您可以使用`mo...。
本站公告 2024-09-16 14:12:49

枚舉窗口是一種遍歷所有或特定一組窗口的方法,在WindowsAPI中,EnumChildWindows函數(shù)用于枚舉指定父窗口的所有子窗口,而EnumWindows函數(shù)用于枚舉整個系統(tǒng)中的所有頂級窗口,hWndChildAfter參數(shù)EnumChildWindows函數(shù)的hWndChildAfter參數(shù)指定枚舉從哪個子窗口開始,它可以是...。
互聯(lián)網(wǎng)資訊 2024-09-15 23:43:58

群策群力,后臺管理系統(tǒng)提升團隊協(xié)作的利器前言在當(dāng)今飛速發(fā)展的數(shù)字時代,團隊協(xié)作對于企業(yè)的成功至關(guān)重要,后臺管理系統(tǒng)作為一種集中的平臺,能夠有效提升團隊協(xié)作效率,實現(xiàn)知識管理,促進業(yè)務(wù)增長,本文將深入探討后臺管理系統(tǒng)在群策群力方面的優(yōu)勢,為企業(yè)提供切實可行的解決方案,一、集中化文件和資源管理后臺管理系統(tǒng)最主要的優(yōu)勢之一在于其能夠提供一個...。
本站公告 2024-09-15 18:41:06
03cul>,語法易學(xué),Dart的語法與其他流行語言,如Java和JavaScript,相似,使得開發(fā)人員很容易上手,類型安全,Dart的類型系統(tǒng)有助于防止錯誤,提高代碼質(zhì)量和可維護性,高性能,Dart編譯為高效的本機代碼,提供出色的性能,跨平臺,Dart應(yīng)用程序可以在各種平臺上運行,為開發(fā)人員提供更大的靈活性,豐富的生態(tài)系統(tǒng),D...。
技術(shù)教程 2024-09-13 15:41:56
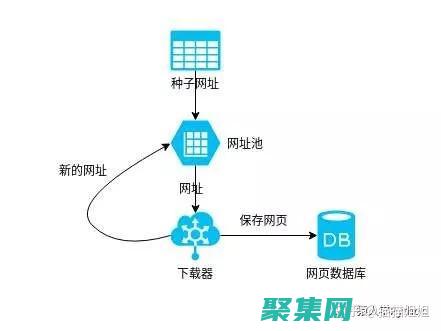
你是否曾經(jīng)想知道互聯(lián)網(wǎng)上龐大的信息是如何收集和組織的呢,這就是爬蟲程序發(fā)揮作用的地方,爬蟲程序是自動化軟件,可以從網(wǎng)絡(luò)上抓取和提取數(shù)據(jù),為我們提供對網(wǎng)絡(luò)背后寶藏的訪問權(quán)限,爬蟲程序的工作原理爬蟲程序的工作方式類似于蜘蛛網(wǎng),它們從一個起點開始,通常是某個網(wǎng)站的主頁,它們會提取頁面上的鏈接并將其添加到隊列中,爬蟲程序會跟隨隊列中的鏈接,抓...。
最新資訊 2024-09-12 23:04:15

簡介小程序支付回調(diào)是小程序開發(fā)中非常重要的一個環(huán)節(jié),通過回調(diào),開發(fā)者可以獲取到支付結(jié)果并進行相應(yīng)的處理,本文將詳細(xì)介紹小程序支付回調(diào)的各個方面,包括回調(diào)流程、回調(diào)參數(shù)、回調(diào)處理以及常見問題解決,回調(diào)流程小程序支付回調(diào)的流程如下,用戶發(fā)起小程序支付請求支付成功后,微信支付服務(wù)器會向小程序服務(wù)器發(fā)送支付結(jié)果通知小程序服務(wù)器收到支付結(jié)果通知...。
互聯(lián)網(wǎng)資訊 2024-09-11 01:19:45

歡迎來到單片機C語言編程的循序漸進之旅!文章專為初學(xué)者設(shè)計,將帶你踏上令人振奮的嵌入式系統(tǒng)編程之旅,什么是單片機,單片機是一種小型的計算機,專門嵌入在設(shè)備中,以控制其功能,它們通常用于微控制器、傳感器和執(zhí)行特定任務(wù)的家用電器中,為什么選擇C語言,C語言是一種低級語言,非常適合單片機編程,它提供了對硬件的精確控制,同時仍然易于學(xué)習(xí)和使用...。
技術(shù)教程 2024-09-10 08:01:07

在當(dāng)今快節(jié)奏的物聯(lián)網(wǎng),IoT,時代,設(shè)備的連接性和功能至關(guān)重要,嵌入式Linux驅(qū)動程序在增強設(shè)備能力方面發(fā)揮著關(guān)鍵作用,使其能夠與傳感器、外圍設(shè)備和網(wǎng)絡(luò)連接,在本指南中,我們將探索如何利用嵌入式Linux驅(qū)動程序設(shè)計來提升您的設(shè)備功能,嵌入式Linux驅(qū)動程序概述嵌入式Linux驅(qū)動程序是軟件組件,用于在嵌入式Linux系統(tǒng)與硬件設(shè)...。
互聯(lián)網(wǎng)資訊 2024-09-09 13:07:07

汶川地震是一場毀滅性的自然災(zāi)害,造成數(shù)萬人死亡,除了巨大的損失和痛苦之外,地震還留下了一些令人不安的證據(jù),讓人們不禁懷疑超自然現(xiàn)象的可能性,異象和預(yù)兆據(jù)報道,在2008年5月12日地震前幾周,人們看到了奇怪的天文現(xiàn)象,如火球和流星雨,一些動物表現(xiàn)出了異常行為,例如蛇爬出地洞,魚從水池中跳出,有傳言稱,有人在夢中看到了地震,并得到了關(guān)于...。
互聯(lián)網(wǎng)資訊 2024-09-05 05:45:52

真實的恐懼,中國十大真實發(fā)生的靈異事件揭秘,真實的恐懼2,導(dǎo)語,靈異事件,一直是人們津津樂道的話題,雖然科學(xué)無法證明其真實性,但民間流傳的眾多故事卻令人毛骨悚然,今天,我們就來為大家揭秘中國歷史上十大真實的靈異事件,帶你領(lǐng)略真實的恐懼,1.北京故宮,午門現(xiàn)鬼頭,北京故宮,這座見證了中國歷史興衰的恢弘建筑,也流傳著不少靈異故事,其中最著...。
互聯(lián)網(wǎng)資訊 2024-09-04 01:15:08